Цель
Цель раздела - ознакомление с концептуальным проектирование БД, обоснование выбора реляционной модели данных и знакомство с историей её создания, терминологией и структурой данных, описанием отношений на этапе логического проектирования реляционной БД.
2.1. Концептуальное проектирование БД
Непосредственное проектирование БД (рис. 1.3) начинается с концептуального моделирования. Это наиболее общее описание, которое называется схемой БД. Схема создается с помощью языка определения данных СУБД, выбранной для реализации проекта. Она не даёт возможности представить данные так, чтобы полученную схему понимали пользователи всех категорий.
Для выхода из этой ситуации данных представляют в виде модели данных – интегрированного набора понятий для их описания, связей между ними и ограничений, на них накладываемых [1, 2, 4, 6, 9…11]. Это необходимо для того, чтобы все участники проекта смогли познакомится с набором правил и однозначно понимать их, поскольку по ним будуте построена БД с определенными типами доступных операций и набором ограничений, которые поддерживают целостность и гарантирует корректность используемых данных.
Концептуальное проектирование БД заключается в выборе или создании модели представления данных технологического процесса, которая не зависит от любых аспектов ее физического размещения, организации и обработки [4].
Выбор или создание модели представления данных базируется на анализе требований пользователей конечной системы. Модель не зависит от типа выбранной СУБД, набора прикладных программ, которые созданы или будут созданы, используемых языков программирования, самой вычислительной платформы и т.д. Модель представления данных, которая получена в результате концептуального проектирования, является источником информации для фазы логического проектирования БД. Если ни одна из существующих моделей (реляционная, сетевая, иерархическая, объектно-ориентированная и т.п.) Вам не подошла, то в этом случаи есть необходимость создавать собственную модель представления данных.
Далее будем считать, что по результатам концептуального проектирования выбрана реляционная модель исходя из того, что 80% современных СУБД поддерживают именно её. А многие не реляционные системы теперь обеспечиваются реляционным пользовательским интерфейсом, независимо от используемой базовой модели.
2.2. История реляционной модели
Реляционная модель впервые была опубликована Э.Ф.Коддом (E.F.Codd) в 1970 году в статье "Реляционная модель данных для больших совместно используемых банков данных". Эту статью принято считать поворотным пунктом в истории развития систем БД, хотя следует заметить, что еще раньше была предложена модель, основанная на множествах (Childs, 1968) [1, 4, 6, 7, 9, 10, 12].
Цели создания реляционной модели формулировались так [4]:
- Обеспечение максимально возможной степени независимости прикладных программ от данных.
- Создание прочного фундамента для решения семантических вопросов, а также проблем непротиворечивости и избыточности данных.
- Расширение языков управления данными за счет включения операций над множествами.
Наиболее значительные исследования возможностей реляционной модели были проведены в рамках трех проектов.
Первый из них разрабатывался в конце 70-х годов корпорацией IBM в городе Сан-Хосе, штат Калифорния, под руководством Астрахана (Astrahan). Его результатом стало создание системы под названием "System R", являвшейся прототипом истинно реляционной СУБД [12]. Этот проект был задуман с целью получения реальных доказательств практичности реляционной модели. Он стал важнейшим источником информации о таких проблемах реализации, как управление параллельностью, транзакциями, оптимизация запросов, безопасности и целостности данных, технология восстановления, учет человеческого фактора и разработка интерфейса пользователя.
Выполнение проекта способствовало появлению научніх статей и созданию других прототипов реляционных СУБД, и в итоге позволило [4]:
- разработать язык управления данными SQL, либо по буквам "S-Q-L" иногда с помощью мнемонического имени "See-Quell", который и теперь имеет статус формального стандарта ISO (International Organization for Standardization) и фактически является отраслевым стандартом языка реляционных СУБД;
- создать различные коммерческие реляционные СУБД, которые впервые появились на рынке в начале 80-х годов, например, DB2 и SQL/DS корпорации IBM, а также ORACLE корпорации ORACLE Corporation.
Вторым проектом, который сыграл заметную роль в разработке реляционной модели данных, был INGRESS (INteractive GRaphics REtrieval System), причом работа над ним проводилась в Калифорнийском университете (город Беркли) почти в то же самое время, что и над проектом System R [12]. Проект INGRESS включал разработку прототипа реляционной СУБД и имел те же цели, что и проект System R. Эти исследования спосбствовали появлению академической версии INGRESS, которая зделала существенный вклад в общее признание реляционной модели данных. Позже от данного проекта отпочковались коммерческие продукты INGRESS фирмы Relational Technology Inc. (теперь CA-Open Ingress фирмы Computer Associates) и Intelligent Database Machine фирмы Britton Lee Inc.
Третьим проектом была система Peterlee Relational Test Vehicle научного центра корпорации IBM, расположенного в городе Петерли, Великобритания (Todd, 1976) [12]. Этот проект был более теоретический, чем проекты System R и INGRESS. Его результаты имели очень большое и даже принципиальное значение, особенно в таких областях, как обработка запросов и оптимизация, а также функциональные расширения системы [4].
Кроме того, позже для более полного и точного отображения смысла данных (Codd, 1979), поддержки объектно-ориентированых понятий(Stonebreaker and Rowe, 1986) и дедуктивных возможностей (Gardarin and Valduriez, 1989), границы реляционной модели данных были разширены.
Такими образом коммерческие системы на основе реляционной модели данных начали появляться в конце 70-х - начале 80-х годов. В настоящее время существует несколько сотен типов различных реляционных СУБД как для мейнфреймов, так и для персональных компьютеров, хотя многие из них не полностью удовлетворяют точному определению реляционной модели данных. Примерами реляционных СУБД для персональных компьютеров являются Oracle и MySQL от Oracle, Access, FoxPro и SQL-Server от Microsoft, InterBase фирмы Embarcadero, RBase фирмы Microrim и т.д.
2.3. Структура данных в реляционной модели
2.3.1. Отношение
Реляционная модель основана на математическом понятии отношения [4, 6, 12, 13]. Допустим, у нас есть два множества, D1 и D2, где D1={2,4} и D2={1,3,5}. Декартовым произведением этих двух множеств (обозначается как D1 × D2) называется набор из всех возможных пар, в которых первым идет элемент множества D1, а вторым - элемент множества D2. Альтернативный способ выражения этого произведения заключается в поиске всех комбинаций элементов, в которых первым идет элемент множества D2, а вторым - элемент множества D1. В результате получим:
D1 × D2={(2, 1), (2, 3), (2, 5),(4, 1), (4,3), ( 4, 5)}.
Любое подмножество этого декартового произведения является отношением. Например, в нем можно выделить отношение R:
R = {(2, 1), (4, 1)}.
Для определения тех возможных пар, которые будут входить в отношение, можно задать некоторые условия их выборки. Например, если обратить внимание на то, что отношение R содержит все возможные пары, в которых второй элемент равен 1, то определение отношения R можно сформулировать следующим образом:
R = {(x, y),| x є D1, y є D2, y = 1}.
На основе тех же множеств можно сформировать другое отношение, S, в котором первый элемент всегда должен быть в два раза больше второго. Тогда определение отношения S можно сформулировать так:
S = {(x, y),| x є D1, y є D2, x = 2 × y}.
В данном примере только одна возможная пара данного декартового произведения соответствует этому условию:
S = {(2, 1)}.
Понятие отношения можно легко распространить и на три множества. Пусть имеется три множества: – D1, D2 и D3. Декартово произведение D1 × D2 × D3 этих трех множеств является набором, котрый состоит из всех возможных троек элементов, в которых первым идет элемент множества D1, вторым – элемент множества D2, а третьим – элемент множества D3. Любое подмножество этого декартового произведения является отношением. Вычислим декартово произведение трех множеств D1={1,3}, D2={2,4} и D3={5,6}:
D1 × D2 × D3 = {(1, 2, 5), (1, 2, 6), (1, 4, 5), (1, 4, 6), (3, 2, 5), (3, 2, 6), (3, 4, 5), (3, 4, 6)}.
Любое подмножество из приведенных выше троек элементов является отношением. Увеличивая количество множеств, можно дать обобщенное определение отношения на n доменах.
Пусть имеется n множеств D1, D2, …, Dn. Декартово произведение для этих n множеств можно определить следующим образом:
D1 × D2 × … × Dn = {() | d<1 є D1, d<2 є D2, … d<n є Dn}.
Обычно это выражение записывают в таком виде: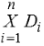 .
.
Любое множество n-арных кортежей этого декартового произведения является отношением n множеств. Обратите внимание на то, что для определения этих отношений необходимо указать множества, или домены, из которых выбираются значения.
Физическим представлением отношения является таблица.
Отношение – это плоская таблица, состоящая из столбцов и строк.
В реляционной модели отношения используются для хранения информации о субъектах (сущностях), которые представлены в БД.
2.3.2. Описание структуры отношения
Атрибут – это поименованный столбец отношения.
Отношение обычно имеет вид двумерной таблицы, в которой строки соответствуют отдельным записям, а столбцы - атрибутам. При этом атрибуты могут располагаться в любом порядке - независимо от их переупорядочивания отношение будет оставаться одним и тем же, а потому иметь тот же смысл. Каждый атрибут реляционной БД определяется на некотором домене.
Домен – это набор допустимых значений для одного или нескольких атрибутов.
Домен - это чрезвычайно важный компонент реляционной модели. Он могет отличаться для каждого из атрибутов, но два и более атрибута могут определяться на одном и том же домене. Пользователь с его помощью может централизованно раскрывать смысл и источник значений, которые получают атрибуты. Таким образом, при выполнении реляционной операции системе доступно больше информации. Это позволяет ей избежать семантически некорректных операций. Например, бессмысленно сравнивать фамилию автора с названием книги, даже если для обоа этих атрибута определены на доменах, базирующихся на символьных строках. С другой стороны, помесячная арендная плата объекта недвижимости и количество месяцев, в течение которых он сдавался в аренду, принадлежат разным доменам (первый атрибут имеет денежный тип, а второй – целочисленный). Однако умножение значений из этих доменов является допустимой операцией. Как следует из этих двух примеров, обеспечить полную реализацию понятия домена совсем непросто, а потому во многих реляционных СУБД они поддерживаются не полностью, а лишь частично.
Элементами отношения являются кортежи или строки таблицы. Кортежи могут располагаться в любом порядке, при этом отношение будет оставаться тем же самым, а значит, и иметь тот же смысл.
Кортеж – это строка отношения.
Описание структуры отношения вместе со спецификацией доменов и любыми другими ограничениями возможных значений атрибутов иногда называют его заголовком (или содержанием (intension)). Обычно оно является фиксированным, до тех пор, пока смысл отношения не начнет изменяться за счет добавления в него дополнительных атрибутов. Кортежи называются расширением (extension), состоянием (state) или телом отношения, которое постоянно меняется.
Степень отношения определяется количеством атрибутов, которое оно содержит.
Отношение только с одним атрибутом имеет степень 1 и называется унарным (unary) отношением (или 1-арным кортежем). Отношение с двумя атрибутами называется бинарным (binary), отношение с тремя атрибутами – тернарным (ternary), а для отношений с большим количеством атрибутов используется термин n-арный (n-агу). Определение степени отношения является частью заголовка отношения.
Кардинальность – это количество кортежей, которое содержит отношение.
Эта характеристика меняется при каждом добавлений или удалении кортежей. Кардинальность является свойством тела отношения и определяется текущим состоянием отношения в произвольно взятый момент.
2.3.3. Реляционная схема
Реляционная схема – это имя отношения, за которым следует множество пар имен атрибутов и доменов.
Например, для атрибутов A1, A2, …, An с доменами D1, D2, …, Dn реляционной схемой будет множество {A1:D1, A2:D2, … An:Dn}. Отношение R, заданное реляционной схемой S, является множеством отображений имен атрибутов на соответствующие им домены. Таким образом, отношение R является множеством таких n-арных кортежей {A1:d1, A2:d2, … An:dn}, где {d1:D1, d2:D2, … dn:Dn}.
Каждый элемент n-арного кортежа состоит из атрибута и значения этого атрибута. Обычно при записи отношения в виде таблицы имена атрибутов перечисляются в заголовках столбцов, а кортежи образуют строки формата d1, d2, …, dn, где каждое значение берется из соответствующего домена. Таким образом, в реляционной модели отношение можно представить как произвольное подмножество декартового произведения доменов атрибутов, тогда как таблица – это всего лишь физическое представление такого отношения.
2.3.4. Свойства отношений
- Отношение имеет уникальное имя в БД.
- Каждая ячейка отношения содержит только неделимое значение.
- Каждый атрибут имеет уникальное имя.
- Значения атрибута берутся из одного домена.
- Порядок следования атрибутов не имеет никакого значения.
- Каждый кортеж отношения является уникальным.
- Теоретически порядок следования кортежей в отношении не имеет значения. (Однако на практике этот порядок может существенно повлиять на эффективность доступа к данным.)
Большая часть свойств отношений БД происходит от свойств математических отношений.
- Поскольку отношение является множеством, то порядок расположения в нем элементов не имеет значения. Следовательно, порядок кортежей в отношении несущественен.
- В множестве не может быть повторяющихся элементов. Аналогично, отношение не может содержать кортежей-дубликатов.
- При вычислении декартового произведения множеств с простыми однозначными элементами (например, целочисленными значениями), каждый элемент в каждом кортеже имеет единственное значение. Аналогично, каждая ячейка отношения содержит только одно значение. Однако математическое отношение не нуждается в нормализации. В своей работе Кодд предлагает запретить наличие повторяющихся групп с целью упрощения реляционной модели данных.
- Набор возможных значений для данной позиции отношения определяется множеством или доменом. В отношении БД все значения в каждом атрибуте должны происходить от одного и того же домена, на котором определен атрибута.
Однако в математическом отношении порядок следования элементов в кортеже имеет значение. Например, допустимая пара значений (1, 2) совершенно отлична от допустимой пары (2, 1). Это утверждение неверно для отношений в реляционной модели, где специально оговаривается, что порядок атрибутов несущественен. Однако, если структура отношения уже определена, то порядок элементов в кортежах тела отношения должен соответствовать порядку имен атрибутов.
2.3.5. Реляционные ключи
Реляционные ключи служат для уникальной идентификации каждого отдельного кортежа отношения по значениям его атрибутов.
Суперключ (super key) – это атрибут или множество атрибутов, которое единственным образом идентифицирует кортеж данного отношения.
Поскольку суперключ может содержать дополнительные атрибуты, которые необязательны для уникальной идентификации кортежа, нас будут интересовать суперключи, состоящие только из тех атрибутов, которые действительно необходимы для уникальной идентификации кортежей. Таким образом в состав суперключа может входить несколько потенциальных ключей.
Потенциальный ключ – это суперключ, который не содержит подмножества, также являющегося суперключом данного отношения. Отношение может иметь несколько потенциальных ключей.
Если ключ состоит из нескольких атрибутов, то он называется составным ключом.
Потенциальный ключ для данного отношения обладает двумя свойствами.
Уникальность.. В каждом кортеже отношения значение ключа единственным образом идентифицирует этот кортеж.
Минимальность. Ни один из атрибутов не может быть выведен из состава ключа без нарушения уникальности.
Обратите внимание на то, что любой конкретный набор кортежей отношения нельзя использовать для доказательства того, что некий атрибут или комбинация атрибутов являются потенциальным ключом. Тот факт, что в некоторый момент времени не существует значений-дубликатов, совсем не означает, что их не может быть вообще. Однако наличие значений-дубликатов в конкретном существующем наборе кортежей вполне может быть использовано для демонстрации того, что некоторая комбинация атрибутов не может быть потенциальным ключом. Для идентификации потенциального ключа требуется знать смысл используемых атрибутов в "реальном мире". Только это позволит обоснованно принять решение о возможности существования значений-дубликатов. Исходя только из подобной семантической информации, можно гарантировать, что некоторая комбинация атрибутов является потенциальным ключом отношения.
Первичный ключ – это потенциальный ключ, который выбран для уникальной идентификации кортежей внутри отношения.
Поскольку отношение не содержит кортежей-дубликатов, то всегда можно уникальным образом идентифицировать каждую его строку. Это значит, что отношение всегда имеет первичный ключ. В худшем случае все множество атрибутов может использоваться как первичный ключ, но обычно, чтобы различить кортежи, достаточно использовать несколько меньшее подмножество атрибутов. Потенциальные ключи, которые не выбраны в качестве первичного ключа, называются альтернативными ключами.
Внешний ключ – это атрибут или множество атрибутов внутри отношения, которое соответствует потенциальному ключу некоторого (может быть, того же самого) отношения.
Отношение, в котором находится потенциальный ключ, называют базовым, а иногда целевым или родительским отношением. Отношение с внешним ключом называют дочерним отношением.
2.3.6. Реляционная БД
Реляционная БД – набор нормализованных отношений.
Реляционная БД состоит из отношений, структура которых определяется с помощью особых методов, называемых нормализацией (normalization).
2.3.7. Описание структуры реляционных данных на разных этапах проектирования
На концептуальном уровне описывается модель представления данных в строгих математических терминах реляционной алгебры, которые определяют их структуру, методы управления и методы обеспечения целостности данных. В любой реляционной СУБД предполагается, что пользователь воспринимает БД как набор связанных между собой таблиц. Такое восприятие не относится к физической структуре БД, где речь идет о её реализации на вторичных носителях с указанием структур хранения и методов доступа, используемых для организации их эффективной обработки. На этапе физического проектирования отношение называется файлом (file), кортежи – записями (records), а атрибуты – полями (fields) и т.д. (табл. 2.1).
Таблица 2.1
Термины, описывающие структуру данных в реляционной модели | Концептуальное проектирование | Логическое проектирование | Физическое проектирование |
| Отношение | Таблица | Файл |
| Кортеж | Строка | Запись |
| Атрибут | Столбец | Поле |
| Степень отношения | Количество столбцов | Количество полей |
| Кардинальность | Количество строк | Количество записей |
| Ключ | Ключ | Индекс |
2.4. Логическое проектирование БД
Логическое проектирование БД это процесс создания схемы БД (логической модели БД) с учетом выбранной модели представления данных, но независимой от типа целевой СУБД и других физических аспектов реализации [4, 6].
Цель логического проектирования состоит в создании логической модели БД для исследуемой части предприятия. Модель представления данных, полученная на этапе концептуального проектирования, является основой логической модели данных, которая учитывает особенности бизнес-процессов исследуемой организации и их реализации в выбранной СУБД. Однако, на этом этапе игнорируются все остальные аспекты выбранной СУБД – например, любые особенности физической организации ее структур хранения данных и построения индексов.
Логическая модель данных является источником информации для этапа физического проектирования и обеспечивает разработчика физической БД средствами нахождения компромиссов, необходимых для достижения поставленных целей. Она также играет важную роль на этапе эксплуатации и сопровождения уже готовой системы. При правильно организованном сопровождении, поддерживаемая в актуальном состоянии логическая модель данных позволяет точно и наглядно представить любые вносимые в БД изменения, а также оценить их влияние на прикладные программы и данные, уже имеющихся в БД.
Логическая модель, отражающая особенности представления о функционировании предприятия одновременно многих типов пользователей, называется глобальной логической моделью данных. Существует два основных подхода к созданию глобальной логической модели данных предприятия – это централизованный и на основе интеграции представлений.
Централизованный подход заключается в слиянии требований отдельных пользователей, выраженных в виде различных представлений, в единый набор требований всех пользователей, который используется для создания глобальной логической модели данных.
Характерной особенностью централизованного подхода является то, что списки требований составляются до создания глобальной логической модели данных. Этот подход применим только при условии, что описываемая БД не слишком велика или сложна.
Метод интеграции представлений заключается в слиянии отдельных локальных логических моделей данных, отражающих представления различных групп пользователей, в единую глобальную логическую модель данных.
Этот подход более управляем, поскольку вся работа предварительно разделяется на мелкие и легко контролируемые части. Трудности обычно возникают лишь при попытках слияния локальных моделей данных, созданных разными разработчиками, которые могут использовать различные термины для одного и того же понятия или, наоборот, связывать один и тот же термин с разными понятиями.
Логическое проектирование БД – важнейший этап, обеспечивающий общий успех разработки системы в целом. Если созданный проект не является точным отражением методов работы и структуры предприятия, то будет очень сложно, если вообще возможно, определить все необходимые пользователям представления (внешние схемы) или организовать поддержку целостности БД. Кроме того, могут возникнуть трудности с физической реализацией БД или обеспечением приемлемой производительности системы. В то же время способность адаптации к изменениям является признаком удачно спроектированной БД. Следовательно, всегда имеет смысл потратить необходимое время и энергию на создание наилучшей из возможных логической модели.
2.5. Пример логической модели
Допустим, что Вам поставлена задача создать БД, позволяющую оперативно давать информацию о прогульщиках занятий. Необходимо, чтобы было известно по каждому прогульщику, сколько часов и какой предмет он не посещал.
Разделим информацию, которая содержится в БД на два типа: справочную и оперативную. Исходя из этого, в нашей БД учета посещаемости занятий напрашиваются две справочные таблицы: «Студенты» и «Предметы», и одна таблица с оперативной информацией «Посещаемость», в которой будем вести учет посещаемости студентов (рис. 2.1). Остается добавить, что сначала необходимо вносить данные в таблицы, которые относятся к справочной информации, а затем – к оперативной.
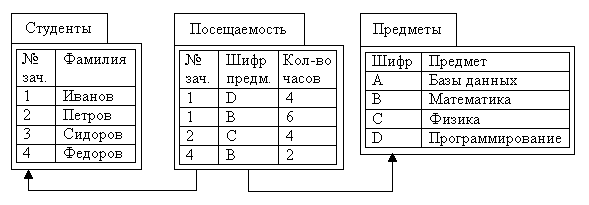
Рис. 2.1. БД учета посещаемости занятий
Обратите внимание, что в столбце «№ зач. кн.» таблицы «Посещаемость» находятся только значения, содержащиеся в столбце «№ зач. кн.» таблицы «Студенты», а в столбце «Шифр пр.» таблицы «Посещаемость» - только значения, содержащиеся в столбце «Шифр» таблицы «Предметы». Таким образом, можно по № зачетной книжки из таблицы «Посещаемость» узнать фамилию прогульщика, а по шифру предмета определить его название. С другой стороны, можно сказать, кто из студентов не пропустил ни одной лекции, и какой предмет посещают все студенты. Попробуйте назвать фамилию добросовестного студента самостоятельно, и лекции по каому предмету никто не прогуливает.
При проектировании всегда смотрите на создаваемую БД с двух сторон: со стороны разработчика и со стороны пользователя. Для разработчика важно без проблем вносить в БД информацию и извлекать ее в том виде, который устраивает пользователя. Для пользователя важно получать информацию в удобной для себя форме. Соблюсти баланс этих интересов подчас непросто. Особенно, когда накладывается лимит времени, за который пользователь хочет получить необходимые данные.
На рис. 2.1 представлен взгляд БД со стороны разработчика. Попробуйте самостоятельно представить таблицу, в которой Вам было бы удобно увидеть сколько и по какому предмету было пропущено занятий каждым студентом. Этот вопрос мы рассмотрим дальше, когда будем изучать «Представления данных».
Такая кажущаяся простота не должна Вас обманывать. Только опыт создания БД поможет Вам выработать свои собственные приемы и подходы. В предлагаемом курсе рассмотрены концепции и приемы проектирования и зоздания БД, с которыми полезно ознакомиться и взять их за основу.
- Цель и суть концептуального проектирования БД?
- На каких составляющих базируется реляционная структура данных?
- Каким образом связаны декартово произведение и двухмерная таблица?
- Из чего состоит структура отношения и какие характеристики оно имеет?
- Какие свойства отношений Вам известны?
- Дайте определения известным Вам реляционным ключам.
- Какие свойства потенциального ключа Вам известны?
- Цель и суть логического проектирования БД?
- Сравните известные Вам подходы к созданию логической модели БД.
Вывод
Концепция реляционной организации данных на практике довела свою жизнеспособность, оставив за собой порядка 80% мирового рынка СУБД. Гибкие подходы логического моделирования реляционных БД дают широкие возможности наглядно реализовать как простые так и достаточно сложные бизнес-процессы для широкого круга пользователей разной квалификации.