Purpose
The main point of this chapter is to get acquainted with the normalization procedure, with different levels, theoretical and practical aspects, criterions of the practical definition of normalization level according to the demands of the end users.
3.1. Normalization procedure
From one side the DB structure designing is a creative work that can be ambiguous, from the other side its key points can be formalized [4…7, 10, 12]. During the design logic data model is continuously tested and verified to meet the users’ demands. The correctness of logical data model is provided by normalization procedure.
DB normalization procedure is an elimination of data excessiveness and definition of functional dependency. Data excessiveness elimination guarantees the compactness of data sets thanks to the possibility to avoid useless duplication and makes impossible the insert anomaly, exclusion and renewal of tuples after physical implementation. Functional dependency is a dependence that connects attributes within one relation and a single value in another relation.. Functional dependency for relations А and B is usually marked as A→B. This concept helps us "to make one more step" towards domestic concept of relations unification one to one (1:1) or one to a set (1:М).
Rules of normalization or Codd rules as they are used to be called now are very simple and not numerous. At the same time they are rather strict.
Rules of normalization or Codd rules as they are used to be called now are very simple and not numerous. At the same time they are rather strict. There are five different levels of normalization: first normal form (1NF), 2NF, 3NF, Boyce-Codd normal form (BCNF), 4NF, 5NF. However, till today none of relational DBMS supports all five normal forms. This happens because of strict demands to efficiency. The point is that in completely normalized database to implement the request you will need to unite so many tables, that efficiency of such system can’t satisfied demands of users. That is why only first three 1NF, 2NF, 3NF are applied in practice.
Relation represents first normal form (1NF) only if all attributes contain indivisible (atomic) values and there are no groups of attributes with the same values that are repeated within one tuple.
Indivisibility of the attribute’s value means that it is impossible to divide it into smaller parts. For example, if in the field “Familyname Name Patronymic” familyname, name and patronymic are contained, the request indivisibility is not supported (fig. 3.1., a). It is necessary to single out separate attributes Name and Patronymic. Then we will have three attributes of relation “Readers”: “FamilyNamе”, “Name” and “Patronymic” (fig. 3.1, b).
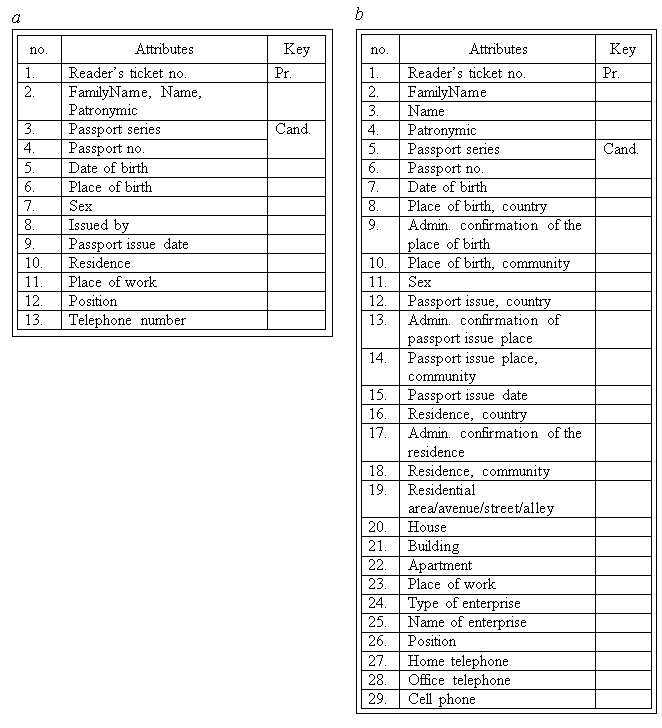
Fig. 3.1. Possible specifications of unnormalized relation «READERS»
The smallest parts can be divided into attributes: «Place of birth» («Country», «Administrative organization», «Community»), «Passport issued by» («Country», «Administrative organization», «Community»), «Place of work» («Type of enterprise», «Name of enterprise»), «Residence» («Country», «Administrative organization», «Community», Residential community / Avenue / Street / Alley», «House», «Building», «Apartment») (fig. 3.1, b).
Indivisibility of the attribute «Telephone number» is not supported because the reader can have several telephone numbers or non (fig. 3.1, а). At first sight, this problem can be resolved the same way as the problem with familyname, name and patronymic that is by separating on the most wide spread types of telephone their own attributes (fig. 3.1, b). However in such case we will face the group of attributes that contain the same values within one tuple. For example: «Home telephone», «Office telephone», «Cell phone».
If we want that relation «READERS» (fig. 3.1, b) corresponds to 1NF it is necessary to remove the group of attributes with telephone numbers that can be repeated within the bounds of one tuple to another relation together with the copy of key attribute «Readers ticket no.»(fig. 3.2). Also it is necessary to single out separate attribute to indicate the telephone number and type. Such decision provides us a possibility first of all, to consider not only three mentioned types of telephones , but also to add new ones, secondly, we can indicate for each reader only telephone types that are real, thirdly, now it is possible to indicate for any reader several telephones of the same type or to indicate non of them.

Fig. 3.2. Reduction of relation «READERS» to 1NF
Relation is represented in the second normal form (2NF) only if it is presented in the first normal form and each non-key attribute is completely defined by primary key. That means that primary key has to determine tuple and should not be redundant (saved with superkey). Attributes that depend on the part of superkey only should be separated in the independent tables.
There is no relation «READERS» (fig. 3.2) in the 2NF. Each tuple is definitely identified by the following attributes: «Reader’s ticket number», «Passport series» and «Passport number». Battery of these attributes is a superkey of this relation. It consists of candidate keys. Each of them can separately identify tuple of relation. In the group of two candidate keys the primary one is a key that has minimal length The presence of both candidate keys is determined by the demands of users.
It is possible to reduce relation «READERS» to the 2NF if we separate relation attributes 2-22 that are related to passport data and copy of primary key «Reader’s ticket number» (fig. 3.3). However thus we will generate relation «PASSPORT DATA». This relation has the same superkey as «READERS» relation before it was reduced to the 2NF. In this case further normalization of «PASSPORT DATA» relation is impossible.
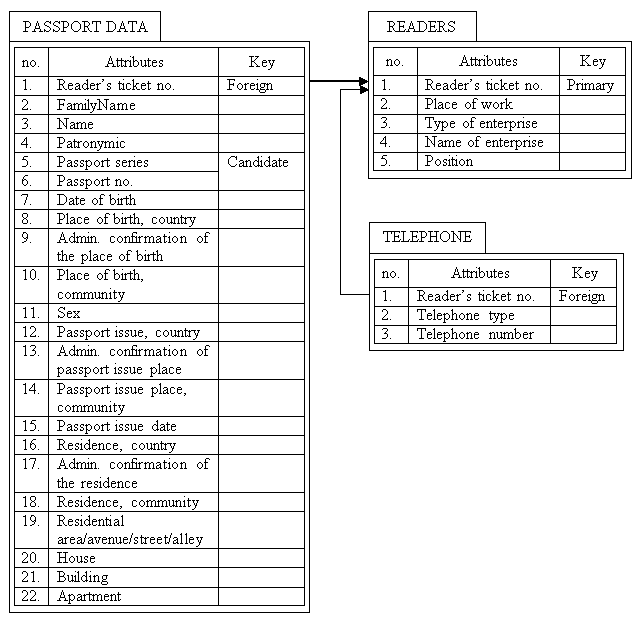
Fig.3.3. Relations «TELEPHONES» and «READERS» reduced to the 2NF
At first glance it seems that in the relation «TELEPHONES» (fig. 3.3) in the logical model description is mentioned that reader’s telephone number is input in full, including code of the country, operator or community and thus candidate key is one that includes only one attribute – «Telephone number». However two different readers can have the same home or office telephone. In such case it is possible to identify tuple definitely using superkey that includes attributes «Reader’s ticket number» and «Telephone number». We can see that superkey is unnecessary. Its content coincides with primary key. That means that relation «TELEPHONES» is represented in the second normal form.
In the general case 1NF and 2NF are considered as an intermediate stage in the process of DB normalization. Most DBMS are oriented to achieve the next level of normalization – third normal form (3NF).It is directly connected to the fact that representation of relation in 3NF is absolutely enough for pretty all practical tasks. For the designing of particularly enormous systems on super-high-speed computers when it is necessary to provide maximal reduction of data volumes it is better to implement further normalization of relations.
The relation is represented in third normal form (3NF) only when it is present in second normal form there are no transitive dependences between non-key attributes that is a value of any relation’s attribute that is not a part of a primary key and doesn’t depend on the value of another attribute that is not a part of a primary key.
This definition is just an original way to express the necessity to represent the system of coupled relations in such way that attributes values of each relation are directly defined by superkey or candidate key of this relation.
There is a method that helps to calculate minimal quantity of relations that are necessary for representation of the DB in the 3NF. If you have put the list of all functional dependencies for your data, it is possible to apply the Bernstein algorithm that is described in any relational algebra textbook.
It seems to be logical that relations with on-line information about the goods in the warehouse include also three following attributes: «Quantity of goods», «Unit price» and «Total value». These are not key attributes. To get the figure of the «Total value» it is necessary to multiply values of attributes «Quantity of goods» and «Unit price». Thus the value of the field «Total value» depends on two attributes that are not included to the primary key. This contradicts the definition of the 3NF. If we want that present relation corresponds to the third normal form it is necessary to remove the attribute «Total value».
Let’s determine that relation «TELEPHONES» and «READERS» (fig. 3.3) are reduced to the third normal form. It happens due to the fact that they are represented in the second normal form and there are no transitive dependencies.
Below an example of 3NF that is called Воусе – Codd normal form – BCNF with much more strict forms is presented.
Relation X is presented in the Воусе – Codd normal form if in each nontrivial functional dependency В→А B is a superkey.
3.5. Forth and fifth normal forms
Before we finish examining Codd rules you will be presented a brief overview of the last two relational DB forms. They are dedicated to manage two more anomalies: multiple-valued and joined relation.
In the X relation there is multiple-valued relation А→В if it is possible that couple of tuples contains А values that are duplicated and at the same time exist other couples of tuples that were received by transposition of В, values that are present in the first couple.
First of all for existence of multiple-valued relation the presence of tuple couples is necessary. А and В can be separate attributes or an aggregation of some attributes set. Long time multiple-valued relation А→В exists if В is a subset of А or А unites B = XS (the bigger relation contain output relation).
Existence of multiple-valued relation creates the anomaly of renewal. 4NF removes short-term multiple-valued relation in relation creating smaller relations. Normalization process is a creation of the biggest possible quantity of small relations to reduce excessiveness of data.
Relation X is presented in the fourth normal form (4NF) only if it is presented in BCNF and for any multiple-valued relation А→В that can be characterized as a long-term relation, or А is a superkey of X table.
Fifth normal form (5NF) can be achieved in case if relation can not be divided into smaller relations by means of designing operations any more.
Designing operations is a decomposition that doesn’t cause the loss of data and when relation is divided into parts so that there is a possibility to join created smaller relations.
3.6. Normalization – advantages and disadvantages
Normalization of DB relations is necessary to remove useless information. As we can see from abovementioned examples normalized DB relations contain only one element of surplus data – attributes of connection that are present at the same time in parent and child relations. As surplus data in relations are not saved, additional space on the information-carrying medium can be saved. However, normalized DB has its disadvantages that are first of all practical.
The quantity of relations in normalized DB depends on the quantity of subjects of the universe of discourse. DB as a part of big systems that manage the vital functions of the companies and enterprises can include hundreds of connected relations. As the threshold of perception of a person doesn’t permit to estimate big quantity of objects with their relations, we can affirm that the increase of normalized relations quantity decreases integral perception of DB as a system of independent data. That is why during the designing and exploitation of big systems very often each employee can imagine processes that occur only in some part of the system. There are some known cases of evolutional designing of such systems when operating principles were already beyond understanding.
Another disadvantage of normalized DB is a necessity to read-out from relations connected data during the implementation of complicated requests that provide the information about interaction of the technological process entities. Working with big volumes of information causes increase of the data access time.
Third normal form and normal form of Воусе – Codd are theoretical constructions while most designers of DB work in real world. That is why it is worth to make some comments about disadvantages that are typical for relations represented in 3NF. There are options when it is better to divide relation into smaller ones, if some part of represented data is not constant and is often renewed (on-line information), and other data are inactive and are rarely renewed (supplemental information). Also it can be useful to unite relations when it is necessary to provide high speed reaction on request. Can be also acceptable to agree with duplication of the data if it provides the possibility to lower consumptions necessary for the requests processing even though formally it would be better not to do such thing.
Also it is necessary to admit that connection between relations should be implemented according to attributes that are absolutely free from semantic dependency that is caused by particularities of real processes running, that reflects DB. For that special incremental attributes of the univocal tuples identification are used. This method helps us to get free from necessity to redefine connections between relations when in real life stocktaking rules of different organization activity subjects are changed.
Abovementioned ideas should not be understood as an appeal to stop normalizing data at all. They are mentioned to show that during the work with data of big volume it is necessary to look for compromise between demands of normalization (that is data “logicality” and saving space on information-carrying mediums) and necessity to improve the operation speed. It is also necessary to pay attention on users’ demands to avoid useless refining subjects of real processes that take place in the enterprise.
If it is not necessary to refine attributes «Place of birth», «Place of passport issue», «Place of work», «Residence», searching for compromise between demands of normalization and operation speed for relation «READERS» (fig.3.1.,a) can cause the situation when it will not even correspond the 1NF (fig. 3.4). Pay attention that passport data of the readers are not separated in the individual relation. This helps us to shorten the time of request execution that gives all possible data about readers as it is not necessary to unite relations «PASSPORT DATA» and «READERS».
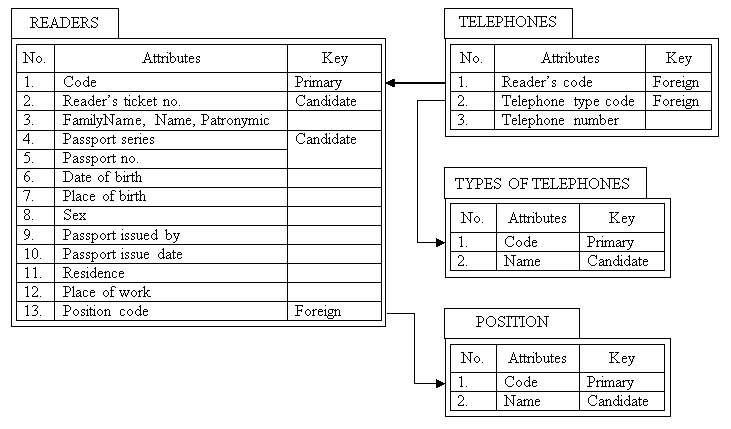
Fig.3.4. The result of relation «READERS» normalization
In contrast to passport data, the information about readers’ telephone numbers is represented in a separate relation (fig.3.4). It happens because the reader can have several contact telephone numbers or non of them. In other words relation 1:M between subjects of the stocktaking of the company in most cases should be implemented by means of two relations. Relation 1:1 in most cases is implemented within one relation.
The benefit of the 1:1 relation implementation between stocktaking objects within more then one relation is proved by necessity to get summarized information from the value of some attribute that is mentioned in the demands of users. This justifies separation of the information about telephone type and position of the reader to another table (fig.3.4). In such case the position and telephone number are indicated only once.
If user will input the name of position or type of the telephone directly to the corresponding attributes of relations “READERS” and “TELEPHONES” (fig.3.3), the designer won’t be able to guarantee that requests will select correct information from the DB. This happens due to the fact that name of the same position or type of the telephone the operator can input with syntax error. In this case standard algorithm of the users’ requests processing will interpret values with the same content according to the corresponding attribute as different ones.
Users' requests to get summarized information can be stated as following: «to display office telephone numbers of the readers with indication of their familynames, names, patronymics, places of work and positions.» Or as following: «to display contact telephone numbers of all assistants with indication of their familynames, names and patronymics.».
The input of incremental attributes «Code» provided the possibility absolutely to get free from the necessity to change characteristics of key attributes due to the modifications of stocktaking rules of the library (fig.3.4). It gives us a possibility to compensate a little bit increase of necessary memory capacity for DB implementation thanks to reduction of space for the relation attribute that joins «READERS» and «TELEPHONES» with relations «POSITION» and «TYPES OF TELEPHONES» correspondingly. These relations could be joined according to the attributes value «name of position» and «name of the telephone type» instead of attributes «Position code» and «Telephone type code». The economy depends on quantity of symbols in these names that is determined according to the demands of user. The result of normalization of relation «READERS» (fig.3.4.) can be different. It depends on the demands of users, experience of designer and on how he understands normalization procedure of relations that are necessary to resolve the task. In our example we have got four relations from one relation «READERS» (fig.3.1, a): «READERS», «TELEPHONES», «TYPES OF TELEPHONES» and «POSITION» (fig.3.4.). Relation «READERS» is normalized. Relation «TELEPHONES» is presented in the 3NF. Relations «TYPES OF TELEPHONES» and «POSITION» are represented in the 1NF.
The outcome of the «LIBRARY» DB relations normalization is a diagram of the links (appendix А). To achieve the compactness there are only key attributes of relations indicated. The connection between logical and physical models can be conveniently expressed after the stage of physical DB designing.
- What options are provided by normalization procedure?
- What normal forms of DB relation you know?
- When relations are represented in the first normal form?
- When relations are represented in the second normal form?
- When relations are represented in the third normal form?
- What normal forms of relations are used in practice?
- What normal forms of relations are rarely used in practice?
- In what cases it is possible to leave relations that are not in 1NF in the DB?
- How to get rid of semantic dependency of the relations links?
- What are the particularities of the 1:1 and 1:M relations implementation?
Conclusion
The necessity to implement the normalization procedure on the stage of logical modeling of relational DB is obvious. During the logical modeling implementation it is necessary to separate theoretical and practical aspects of relational DB normalization. On practice the procedure of normalization is a compromise between reduction of useless data, functional dependencies and access speed, that satisfies end users.