Цель
Цель раздела - ознакомление с процедурой нормализации, её разными уровнями, теоретическим и практическим аспектами, критериями определения уровня нормализации на практике в зависимости от требований конечных пользователей.
3.1. Процедура нормализации
С одной стороны, процесс проектирования структур БД является творческим, неоднозначным, с другой стороны, его узловые моменты могут быть формализованы [4 - 7, 10, 12]. В процессе разработки логическая модель данных постоянно тестируется и проверяется на соответствие требованиям пользователей. Корректность логической модели данных обеспечивает процедура нормализации.
Процедура нормализации БД заключается в устранении избыточности данных и выявлении функциональных зависимостей. Устранение избыточности данных гарантирует компактность набора данных за счет ухода от их ненужного дублирования и исключения возможности возникновения аномалии вставки, удаления и обновления кортежей после физической реализации БД. Функциональная зависимость связывает атрибуты в одном отношении с единственным значением в другом отношении. Функциональную зависимость для отношений А и B принято обозначать как A→B. Это понятие подводит "на один шаг" к родственной концепции объединения отношений связями типа один к одному (1:1) или один ко многим (1:М).
Правила нормализации или правила Кодда, как их теперь принято называть, очень просты и немногочисленны, но весьма строги. В случае применения к отношениям каждое правило описывает следующий уровень соответствия требованиям теории реляционных БД и различные уровни нормализации.
Существует следующие уровни нормализации: первая нормальная форма (1НФ), 2НФ, 3НФ, нормальная форма Бойса-Кодда (БКНФ), 4НФ, 5НФ. Однако, до сегодняшнего дня ни одна из реляционных СУБД не поддерживает все пять нормальных форм. Это является следствием жестких требований к производительности. Суть дела состоит в том, что в полностью нормализованой БД для выполнения запроса будет необходимо соеденить настолько много таблиц, что производительность такой системы не сможет удовлетворить пользователей. Поэтому на практике используют лишь первые три уровня нормализации - 1НФ, 2НФ, ЗНФ.
3.2. Первая нормальная форма
Отношение представлено в первой нормальной форме (1НФ) тогда и только тогда, когда все его атрибуты содержат только неделимые (атомарные) значения и в нем отсутствуют группы атрибутов с одинаковыми по смыслу значениями, которые повторяются в пределах одного кортежа.
Неделимость значения атрибута говорит о том, что его нельзя разделить на более мелкие части. Например, если в атрибуте «Фамилия Имя Отчество» содержится фамилия, имя и отчество читателя, требование неделимости не соблюдается (рис. 3.1, а). Здесь необходимо выделить в отдельные атрибуты имя и отчество. В результате получится три атрибута отношения «ЧИТАТЕЛИ»: «Фамилия», «Имя» и «Отчество» (рис. 3.1, б).

Рис. 3.1. Возможные спецификации ненормализованного отношения «ЧИТАТЕЛИ»
На более мелкие части можно также разделить атрибуты: «Место рождения» («Страна», «Административное образование», «Населенный пункт»), «Место выдачи паспорта» («Страна», «Административное образование», «Населенный пункт»), «Место основной работы» («Тип предприятия», «Название предприятия»), «Место жительства» («Страна», «Административное образование», «Населенный пункт», «Жилой массив / Проспект / Улица / Переулок», «Дом», «Корпус», «Квартира») (рис. 3.1, б).
Для контакта читатель может определить один, несколько или ни одного номера телефона. Таким образом в общем случае информация в атрибуте «Номер телефона» может быть розделена на несколько частей, каждая из которых является отдельным телефонным номером (рис. 3.1, а). На первый взгляд эту проблему можно решить так же, как и для фамилии, имени и отчества, выделив для наиболее распространенных типов телефонов отдельные атрибуты (рис. 3.1, б). Однако, в этом случае, мы столкнемся с повторяющейся группой атрибутов, содержащих одинаковые по смыслу значения в пределах одного кортежа, например: «Домашний телефон», «Рабочий телефон», «Мобильный телефон».
Чтобы отношение «ЧИТАТЕЛИ» (рис. 3.1, б) соответствовало 1НФ необходимо удалить из него группу атрибутов с номерами телефонов, которые повторяются в пределах одного кортежа, в другое отношение вместе с копией ключевого атрибута «№ читательского билета» (рис. 3.2). Причем, выделим для указания номера и типа телефона отдельные атрибуты. Это позволяет: во-первых, учитывать не только три указанных типа телефона, но и добавлять новые и во-вторых, указывать для каждого читателя только те типы телефонов, которые у него имеются, в-третьих, можно указать для любого читателя несколько однотипных телефонов или вообще не указывать ни одного телефонного номера.

Рис. 3.2. Приведение отношения «ЧИТАТЕЛИ» к 1НФ
3.3. Вторая нормальная форма
Отношение представлено во второй нормальной форме (2НФ) тогда и только тогда, когда оно представлено в первой нормальной форме, и каждый неключевой атрибут полностью определяется первичным ключом, то есть чтобы первичный ключ однозначно определял кортеж и не был избыточен (совпадал с суперключом). Те атрибуты, которые зависят только от части суперключа, должны быть выделены в составе отдельных таблиц.
Отношение «ЧИТАТЕЛИ» (рис. 3.2) не представлено во 2НФ. В нём каждый кортеж может быть однозначно идентифицирован следующими атрибутами: «№ читательского билета», «Серия паспорта» и «№ паспорта». Совокупность этих атрибутов является суперключом этого отношения. Он состоит из двух потенциальных ключей, которые по отдельности могут идентифицировать кортежи отношения. Из двух потенциальных ключей в качестве первичного ключа выбран тот, длина которого минимальна. Наличие обоих потенциальных ключей обусловлено требованиями пользователей.
Привести отношение «ЧИТАТЕЛИ» ко 2НФ можно, вынеся в отдельное отношение атрибуты 2 – 22, которые касаются паспортных данных, и копию первичного ключа «№ читательского билета» (рис. 3.3). Однако в результате мы получим отношение «ПАСПОРТНЫЕ ДАННЫЕ», которое имеет такой же суперключ, как и отношение «ЧИТАТЕЛИ», до приведения его ко 2НФ. В нашем случае дальнейшая нормализация отношения «ПАСПОРТНЫЕ ДАННЫЕ» невозможна.
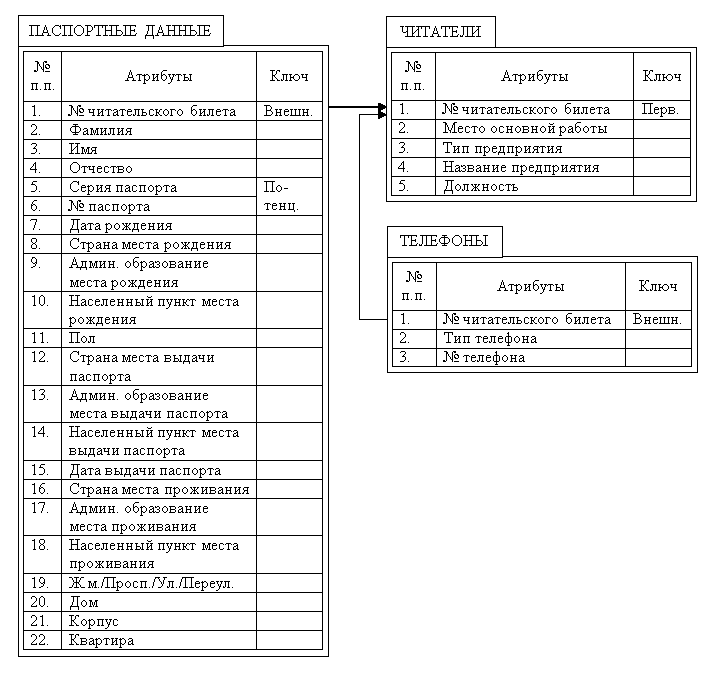
Рис. 3.3. Отношения «ТЕЛЕФОНЫ» и «ЧИТАТЕЛИ», приведенные ко 2НФ
В отношении «ТЕЛЕФОНЫ» (рис. 3.3) на первый взгляд кажется, что если в описании логической модели добавить номер телефона читателя, включая код страны, оператора или населенного пункта, то потенциальным будет ключ, в составе которого всего один атрибут – «№ телефона». Однако, у двух разных читателей может быть один и тот же домашний или рабочий телефоны. Следовательно, однозначно идентифицировать кортежи можно по составному суперключу, в который входят атрибуты «№ читательского билета» та «№ телефона». Мы видим, что суперключ не является избыточным. Его состав совпадает с первичным ключом. Значит отношение «ТЕЛЕФОНЫ» представлено во второй нормальной форме.
3.4. Третья нормальная форма
В общем 1НФ и 2НФ рассматриваются как промежуточные этапы в процессе нормализации БД. Большая часть СУБД ориентирована на достижение следующей степени нормализации - третьей нормальной формы (ЗНФ). Это связано с тем, что представление отношений в 3НФ вполне отвечает почти всем практическим задачам. При разработке исключительно больших систем на сверхбыстродействующих компьютерах, когда необходимо обеспечить максимальное сокращение объемов данных, желательно провести дальнейшую нормализацию отношений.
Отношение представлено в третьей нормальной форме (3НФ) тогда и только тогда, когда оно есть во второй нормальной форме и в нём нет транзитивных зависимостей между неключевыми атрибутами, то есть значение любого атрибута отношения, не входящего в первичный ключ, не зависит от значения другого атрибута, не входящего в первичный ключ.
Это определение – всего лишь оригинальный способ выразить необходимость представления системы связанных отношений в таком виде, чтобы значения атрибутов каждого отношения непосредственно определялись либо суперключом, либо потенциальным ключом этого отношения.
Существует метод расчета минимального числа отношений, необходимых для представления БД в 3НФ. В том случае, если вы составили список всех функциональных зависимостей в Ваших данных, можно применить алгоритм Бернштейна, который описан в любом учебнике реляционной алгебры.
Рассмотрим пример из области учета товара на складе. Кажется логичным, чтобы в отношение с оперативной информацией о товаре на складе входили в числе прочих три следующих атрибута: «Количество товара», «Цена за единицу товара» и «Общая стоимость товара». Они не являются ключевыми. Для получения значения «Общей стоимости товара» необходимо перемножить значения, находящиеся в атрибутах: «Количество товара» и «Цена за единицу товара». Т.е. значение поля «Общей стоимости товара» зависит от значений двух атрибутов, не входящих в состав первичного ключа. Это противоречит определению 3НФ. Чтобы данное отношение соответствовало третьей нормальной форме из него необходимо убрать атрибут «Общая стоимость товара».
Отметим, что отношения «ТЕЛЕФОНЫ» и «ЧИТАТЕЛИ» (рис. 3.3) приведены к третьей нормальной форме. Это следует из того, что они представлены во второй нормальной форме и в них нет транзитивных зависимостей.
Ниже приводится вариант определения 3НФ, называемого нормальной формой Бойса-Кодда (Воусе-Codd) – БКНФ, где устанавливаются более строгие требования.
Отношение X представлено в нормальной форме Бойса-Кодда, если в каждой нетривиальной функциональной зависимости В→А В является суперключом.
3.5. Четвертая и пятая нормальные формы
Прежде чем закончить рассмотрение правил Кодда, Вам будет предложен краткий обзор двух последних форм отнощений реляционных БД. Они предназначены для устранения еще двух аномалий: многозначная зависимость и объединяющая зависимость.
В отношении X существует многозначная зависимость А→В тогда, когда в нем можно обнаружить ситуации, где пара кортежей содержит дублирующееся значение А и одновременно существуют другие пары кортежей, полученные путем перестановки значений В, присутствующих в первой паре.
Прежде всего, для существования многозначной зависимости требуется существование пар кортежей. А и В могут быть как отдельными атрибутами, так и объединением некоторого набора атрибутов. Тривиальная многозначная зависимость для А→В существует в тогда, и только тогда, когда В является подмножеством А или А объединяет B = XS (более крупное отношение содержит исходное отношение).
Существование многозначной зависимости порождает аномалию обновления. 4НФ устраняет нетривиальную многозначную зависимость в отношении посредством создания меньших отношений. Процесс нормализации представляет собой создание как можно большего числа все более мелких отношений в целях сокращения избыточности данных.
Отношение X представлено в четвертой нормольной форме (4НФ) тогда и только тогда, когда оно представлено в БКНФ и для любой многозначной зависимости А→В в этом отношении можно сказать, что эта зависимость либо является тривиальной, либо А является суперключом таблицы X.
Пятая нормальная форма (5НФ) достигается в том случае, когда отношение не может далее разбиваться на более мелкие отношения посредством операции проектирования.
Под операцией проектирования понимается декомпозиция данных (без их потерь), при которой отношение разбивается на части (каждая из которых является отношением) таким образом, чтобы оставалась возможность объединить эти части в исходное отношений.
3.6. Нормализация – за и против
Целью нормализации отношений БД является устранение избыточной информации. Как видно из приведенных выше примеров, нормализованые отношения БД содержат только один элемент избыточных данных – это атрибуты связи, присутствующие одновременно в родительском и дочернем отношениях. Поскольку избыточные данные в отношениях не хранятся, то экономится место на носителях информации. Однако в нормализованной БД есть и недостатки, прежде всего, практического характера.
Чем больше число субъектов (сущностей), охватываемых предметной областью, тем из большего числа отношений будет состоять нормализованная БД. Базы данных в составе больших систем, которые задействованы в жизнедеятельности крупных организаций и предприятий, могут содержать сотни связанных между собою отношений. Поскольку порог человеческого восприятия не позволяет одновременно охватить большое число объектов с учетом их взаимосвязей, то можно утверждать, что с увеличением числа нормализованных отношений целостное восприятие БД как системы взаимосвязанных данных уменьшается. Поэтому при разработке и эксплуатации крупных систем существуют ситуации, когда каждый сотрудник представляет себе процессы, протекающие только в части системы. Известны случаи эволюционного создания таких систем, когда принципы их функционирования впоследствии выходили за границы понимания.
Другим недостатком нормализованной БД является необходимость считывать из отношений связанные данные при выполнении сложных запросов, которые предоставляют информацию о взаимодействии сущностей технологического процесса между собой. При больших объемах данных это приводит к увеличению времени доступа к данным.
Третья нормальная форма и нормальная форма Бойса-Кодда являются теоретическими конструкциями, в то время как большинство разработчиков БД работают в реальном мире. Поэтому уместно сделать несколько замечаний о недостатках, присущих отношениям, представленным в 3НФ. Существуют варианты, когда имеет смысл разделить отношение на более мелкие, если часть представленных в нём данных непостоянна и часто обновляется (оперативная информация), а остальные данные пассивны и изменяются в редких случаях (справочная информация). Также есть смысл объединить отношения, когда необходимо обеспечить высокую скорость реакции на запрос. Можно даже пойти на дублирование данных в таблицах, если это позволит снизить затраты на обработку запросов, хотя формально не следовало бы этого делать.
Необходимо также отметить, что связь между отношениями целесообразно осуществлять по атрибутам, полностью освобожденным от семантической зависимости, которая порождается особенностями реализации реальных процессов, отражаемых в БД. Для этого используют специально выделенные инкрементные атрибуты однозначной идентификации кортежей внутри отношений. Такой прием позволяет уйти от необходимости переопределения связей между отношениями при изменении в реальной жизни правил учета различных субъектов деятельности организации.
Приведенные выше соображения не следует воспринимать, как призыв вовсе не нормализовать данные. Они лишь призваны показать, что при работе с данными большого объема приходится искать компромисс между требованиями нормализации (то есть "логичности" данных и экономии места на носителях информации) и необходимостью улучшения быстродействия. При этом необходимо обращать внимание на требования пользователей, чтобы избегать излишней детализации субъектов реальных процессов, происходящих на предприятии.
Если пользователю нет необходимости детализировать атрибуты «Место рождения», «Место выдачи паспорта», «Место основной работы» и «Место жительства», то поиск компромисса между требованиями нормализации и быстродействием для отношения «ЧИТАТЕЛИ» (рис. 3.1, а) приводит к тому, что, по сути, это отношение может не соответствовать даже 1НФ (рис. 3.4). Обратите внимание, что паспортные данные читателей также не вынесены в отдельную таблицу. Это позволяет сократить время выполнения запроса, который выдает все имеющиеся данные о читателях, за счет отсутствия необходимости соединения отношений «ПАСПОРТНЫЕ ДАННЫЕ» и «ЧИТАТЕЛИ».
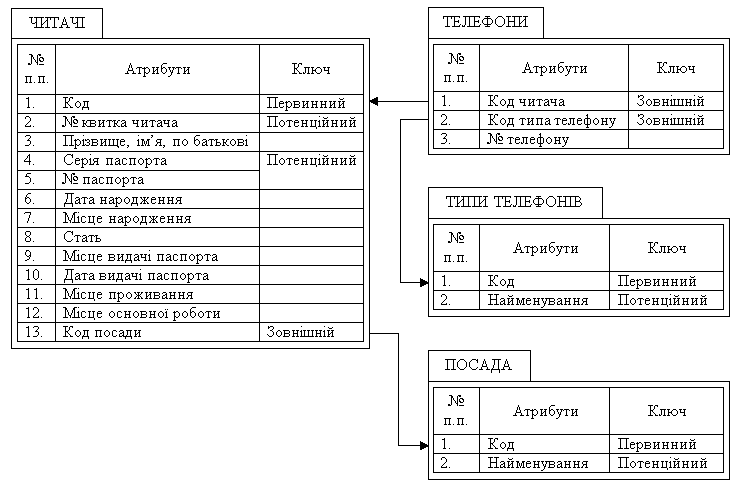
Рис. 3.4. Результат нормализации отношения «ЧИТАТЕЛИ»
В отличие от паспортных данных сведения о телефонных номерах читателей вынесены в отдельное отношение (рис. 3.4). Это связано с тем, что у одного читателя может быть как несколько контактных телефонов, так и не быть их вовсе. Другими словами, связь 1:М между субъектами учета и деятельности организации в подавляющем большинстве случаев необходимо реализовать с помощью двух отношений. Связь 1:1 в большинстве случаев реализуется в одном отношении.
В пользу реализации связи 1:1 между субъектами учета более чем в одном отношении говорит наличие в требованиях пользователей необходимости получения обобщающей информации по значению какого-либо атрибута. Именно это оправдывает вынесение данных о типе телефона и должности читателя в отдельные таблицы (рис. 3.4). В этом случае название должности или типа телефона указывается один раз.
Если пользователи будут вносить название должности или тип телефона непосредственно в соответствующие атрибуты отношений «ЧИТАТЕЛИ» и «ТЕЛЕФОНЫ» (рис. 3.3), то разработчики не смогут гарантировать, что из БД информация по запросам будет извлекаться корректно. Это связано с тем, что название одной и той же должности оператор может внести с синтаксической ошибкой. В этом случае стандартные алгоритмы обработки запросов пользователей к БД будут интерпретировать одинаковые по сути значения атрибута как различные.
Запрос пользователей на получение обобщающей информации может быть сформулирован так: «вывести на экран рабочие номера телефонов читателей с указанием их фамилий, имен, отчеств, мест работы и должностей», или так: «вывести на экран контактные номера телефонов всех ассистентов с указанием их фамилий, имен и отчеств».
Ввод инкрементных атрибутов «Код» позволил полностью освободиться от необходимости изменения свойств ключевых атрибутов в связи изменениями правил учета читателей в библиотеки (рис. 3.4). Они позволили несколько компенсировать увеличение необходимого объема памяти для реализации БД за счет сокращения места для атрибута, связывающего отношения «ЧИТАТЕЛИ» и «ТЕЛЕФОНЫ» с отношениями «ДОЛЖНОСТИ» и «ТИП ТЕЛЕФОНА» соответственно. Эти отношения можно было бы связать по значениям атрибутов «Наименование должности» и «Наименование типа телефона» вместо атрибутов «Код должности» и «Код типа телефона». Экономия зависит от количества знаков этих наименований, которая заложена в требованиях пользователей. Результат нормализации отношения «ЧИТАТЕЛИ» (рис. 3.4) может быть и другим. Он зависит от требований пользователей, от опыта и взгляда разработчика на процедуру нормализации отношений, необходимых для решения поставленной задачи. В нашем примере мы получили из одного отношения «ЧИТАТЕЛИ» (рис. 3.1, а) четыре отношения: «ЧИТАТЕЛИ», «ТЕЛЕФОНЫ», «ТИПЫ ТЕЛЕФОНОВ» и «ДОЛЖНОСТИ» (рис. 3.4). Отношение «ЧИТАТЕЛИ» ненормализовано. Отношение «ТЕЛЕФОНЫ» в 3НФ. Отношения «ТИПЫ ТЕЛЕФОНОВ» и «ДОЛЖНОСТИ» представлены в 1НФ.
Конечнім результатом нормализации отношений БД «БИБЛИОТЕКА» является диаграмма связей между отношениями (приложение А). Для компактности в ней указываются лишь ключевые атрибуты отношений. Связь между логической и физической моделью удобно показывать после этапа физического проектирования БД.
- Что обеспечивает и гарантирует процедура нормализации?
- Какие нормальные формы отношений БД Вам известны?
- Когда отношение представлено в первой нормальной форме?
- Когда отношение представлено во второй нормальной форме?
- Когда отношение представлено в третьей нормальной форме?
- Какие нормальные формы отношений используются на практике?
- Какие нормальные формы отношений редко используются на практике?
- В каких случаях в БД можно оставить отношение, которое не приведено к 1НФ?
- Как избавиться от симантической зависимости в связях между отношениями?
- Какие существуют способы реализации связей 1:1 и 1:М в БД?
Вывод
Необходимость проведения процедуры нормализации на этапе логического моделирования реляционной БД является бесспорной. При реализации логической модели необходимо разделять теоретический и практический аспекты нормализации отношений реляционной БД. На практике процедура нормализации является компромиссом между устранением избыточности данных, функциональных зависимостей и скоростью выборки и обработки данных, которая удовлетворяет конечных пользователей.