Цель
Цель раздела - определение роли СУБД в информационной системе организации как ее неотъемлемого компонента, краткое рассмотрение различных технологий построения СУБД, сравнение их архитектур и ознакомление с жизненным циклом баз данных.
1.1. Информационная система
База данных (БД) – это совместно используемый набор логически связанных данных и их описаний, предназначенный для удовлетворения информационных потребностей организации [4].
Система управления базами данных (СУБД) – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
СУБД является неотъемлемой частью информационной системы организации [1-3].
Информационная система – ресурсы, которые позволяют выполнять сбор, корректировку и распространение информации внутри организации [4].
В состав типичной компьютеризированой информационной системы входят:
- база данных;
- программное обеспечение баз данных;
- прикладное программное обеспечение;
- аппаратное обеспечение, в том числе устройства хранения данных;
- персонал, эксплуатирующий и разрабатывающий эту систему.
1.2. Ручные картотеки – файловые системы – современные СУБД
Дадим характеристику методам хранения и управления данными, которые используются информационными системами организаций [4].
Ручные картотеки позволяют успешно справляться с поставленными задачами обработки информации, если количество хранимых объектов невелико. Они вполне годятся для хранения и извлечения большого количества данных, но совершенно не подходят для тех случаев, когда необходимо установить перекрестные связи или выполнить обработку сведений. Если нам понадобится какая-то информация, то потребуется просмотреть картотеку от начала и до конца, чтобы найти искомые сведения. Для обеспечения нахождения нужной информации предусматривается использование в такой системе некоторого алгоритма индексирования, позволяющего ускорить поиск нужных сведений. Например, можно использовать специальные разделители или отдельные папки для различных логически связанных типов объектов.
Файловые системы – это набор программ, с помощью которых пользователь выполняет некоторые операции, например, создает отчеты. Каждая программа определяет свои собственные данные и управляет ими [2, 4, 5].
Файловые системы были первой попыткой компьютеризировать известные всем ручные картотеки. Они были разработаны в ответ на потребность в получении более эффективных способов доступа к данным. Однако, вместо создания централизованного хранилища всех данных организации, был использован децентрализованный подход, когда сотрудники каждого отдела при помощи специалистов по обработке данных работали со своими собственными данными и хранили их в своем отделе.
Этого вполне достаточно для того, чтобы понять имеющиеся недостатки.
- разделение и изоляция данных;
- дублирование данных;
- зависимость от данных;
- несовместимость форматов файлов;
- быстрое увеличение количества приложений для извлечения информации, необходимой пользователям.
Разделение и изоляция данных приводит к существенным затруднениям, когда необходимо организовать обработку информации, котрая находится в двух и более файлах.
Дублирование данных приводит к неэкономному расходованию ресурсов, поскольку на ввод избыточных данных требуется затрачивать дополнительное время и деньги. Оно может привести к нарушению их целостности. Например, в двух разных отделах организации можно получить на один и тот же вопрос противоречивые ответы. Во многих случаях дублирование данных можно избежать совместным использованием файлов.
Зависимость от данных становится причиной больших затрат при изменении физической структуры файлов, которая отражена в программном обеспечении, работающем с ними. Например, после некоторого времени промышленной эксплуатации прикладной программы выяснилось, что по вновь принятому законодательству номер банковского счета будет увеличен с 10 до 16 знаков. Чтобы выйти из этой ситуации, необходимо написать программу, которая отработает всего один раз. Она должна открыть исходный файл, создать временный файл с новой структурой, считать информацию из исходного файла, преобразовать данные в новый формат и записать их во временный файл, удалить исходный файл, присвоить временному файлу имя исходного.
Несовместимость форматов файлов затрудняет обработку информации еще в большем объеме, чем разделение и изоляция данных. Например, она может быть следствием необходимости совместного использования данных двумя локальными задачами. Для этого понадобиться создавать программное обеспечение, которое конвертирует данные в один общий формат. После чего возможна их совместная обработка.
Быстрое увеличение количества прикладных программ для извлечения информации, необходимой пользователям в файловых системах во многом зависит от программиста, потому что все требуемые запросы и отчеты должны быть созданы именно им. В результате события развивались по одному из двух сценариев. В организациях, где программисты отсутствуют в штатном расписании, типы создаваемых запросов и отчетов имели фиксированную форму, и не было никаких инструментов создания незапланированных или произвольных запросов. В других организациях, где программисты работали, наблюдалось быстрое увеличение количества файлов и прикладных программ. В конечном счете, наступал момент, когда они перестают удовлетворять потребности пользователей в получении необходимой им информации.
Перечисленные ограничения файловых систем являются следствием двух факторов.
- Определение данных происходит внутри прикладных программ, а не хранится отдельно и независимо от них.
- Помимо прикладных программ не предусмотрено никаких других инструментов доступа к данным и их обработки.
Для повышения эффективности работы стали использовать новый подход: БД и СУБД.
Чтобы глубже вникнуть в суть этого понятия, рассмотрим его определение более внимательно. БД – это единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями из разных подразделений. Вместо разрозненных файлов, здесь все данные собраны вместе с минимальной долей избыточности. БД уже не принадлежит какому-то единственному отделу, а является общим корпоративным ресурсом. Причем она хранит не только рабочие данные, но и их описания. Поэтому её еще называют набором интегрированных записей с самоописанием. В совокупности описание данных называется системным каталогом (system catalog), или словарем данных (data-dictionary), а сами элементы описания принято называть метаданными (meta-data), т.е. "данными о данных". Именно наличие самоописания данных обеспечивает независимость между прикладными программами и данными (program-data independents).
На сегодня использование СУБД имеет такие преимущества:
- контроль за избыточностью данных;
- исключение противоречивости данных;
- совместное использование данных;
- поддержка целостности данных;
- повышенная безопасность;
- упрощение масштабирования системы;
- возможность нахождения компромисса при противоречивых требованиях;
- повышение доступности данных и их готовности к работе;
- улучшение показателей производительности;
- упрощение сопровождения системы за счет независимости от данных;
- улучшенное управление параллельной обработкой данных;
- развитые службы резервного копирования и восстановления,
и недостатки:
- сложность;
- размер;
- стоимость;
- дополнительные затраты на аппаратное обеспечение;
- затраты на конвертирование данных;
- более серьезные последствия при выходе системы из строя.
1.3. Сравнение СУБД файл-серверной архитектуры с СУБД архитектуры клиент-сервер
1.3.1. Основные составляющие программного обеспечения СУБД
Сервер это программно-аппаратный комплекс, который обрабатывает запрос.
Он, по существу, ждет, пока клиент сделает запрос, а затем обрабатывает его. Сервер должен обладать способностью обрабатывать одновременно несколько запросов от нескольких клиентов, а также уметь распределять эти запросы по приоритетам. Чаще всего серверная программа работает постоянно, обеспечивая не прекращающийся доступ к ее услугам.
Клиенты представляют собой приложения, обеспечивающие графический или иной интерфейс с пользователем.
Прикладные программы клиентов предоставляют пользователю интерфейс для управления данными на сервере. Именно с помощью прикладной программы пользователь получает доступ к функциональным возможностям сервера. Примером запрашиваемых действий может быть получение, добавление, корректировка и удаление информации или печать отчета. В этом случае клиент просто посылает запрос и предоставляет необходимые для его выполнения данные. Сервер несет ответственность за обработку запроса. Это означает, что клиент может самостоятельно выполнять любые логических действий самостоятельно. Вполне возможно, что клиент реализует большую часть (если не все) бизнес-правила.
Бизнес-правила - это процедуры управления, которые определяют, как клиент должен получать доступ и манипулировать данными на сервере.
Эти правила реализуются программным текстом клиента, сервера или ими обоими. На стороне сервера бизнес-правила реализуются в виде хранимых процедур, триггеров и других объектов, присущих серверной БД. Важно понимать, что бизнес-правила определяют поведение всей системы. При их отсутствии у вас есть просто данные на одном компьютере и приложение с интерфейсом пользователя на другом, однако нет метода их соединения.
Если большая часть правил реализована на сервере, то его называют "толстым сервером". Если правила реализуются в основном на стороне клиента, он называется "толстым клиентом". Если правила реализованы на среднем уровне, то сервер также называют "толстым". Таким образом, объем и тип операций, котрые необходимы для управления данными, определяют место реализации бизнес-правил.
1.3.2. Файл-серверная архитектура СУБД
Со временем БД на персональных компьютерах совершенствовались по направлению от настольных или локальных прикладных программ, когда реально с БД могло работать одна прикладная программа, до систем коллективного доступа к данным [2 – 7].
Необходимость коллективной работы с одними и теми же данными повлекла за собой перенос БД на файловый сервер. Прикладная программа, работающая с БД, располагалось также на сервере. Способ, заключавшийся в хранении прикладной программы, которая обращается к БД, на компьютере пользователя (клиента) не получил широкого распространения. Были выпущены новые версии локальных СУБД, которые позволяли создавать прикладные программы, одновременно работающие с одной БД на файловом сервере. Основной стала проблемой, которая связана с явной или неявной обработкой транзакций, и обеспечением смысловой и ссылочной целостности БД при одновременном изменении данных несколькими клиентами, которая неизбежно возникает при коллективном доступе.
В ходе эксплуатации локальных систем были выявлены следующие недостатки файл-серверного подхода:
- Вся тяжесть вычислительной нагрузки при доступе к БД ложится на прикладную программу клиента, что является следствием принципа обработки информации в системах "файл-сервер": при выдаче запроса на выборку информации из таблицы вся таблица БД копируется на компьютер клиента, где осуществляется выборка.
- Не оптимально расходуются ресурсы компьютера клиента и сети. Например, если в результате запроса мы должны получить 2 записи из файла объемом 10 000 записей, то все они записей будут скопированы с файл-сервера на компьютер клиента. В результате возрастает сетевой трафик, и увеличиваются требования к аппаратным мощностям системы. Заметим, что потребности в постоянном увеличении вычислительных мощностей компьютера клиента обусловливаются не только развитием программного обеспечения, но и возрастанием обрабатываемых объемов информации.
- В БД на файл-сервере гораздо проще вносить изменения в отдельные таблицы непосредственно из инструментальных средств, минуя приложения клиентов. Подобная возможность возникает в связи с тем, что у локальных системах база данных - понятие больше логическое, чем физическое, т.к. под БД понимается набор отдельных файлов, находящихся в едином каталоге на диске. Все это позволяет говорить о низком уровне безопасности как с точки зрения несанкционированного доступа и нанесения вреда, так и с точки зрения внесения ошибочных изменений.
- Бизнес-правила в системах файл-сервер реализуются в прикладных программах. Это позволяет им применять взаимоисключающие бизнес-правила. Смысловая целостность информации при этом может быть нарушиться.
1.3.3. Архитектура клиент-сервер
Приведенные недостатки решаются при переводе приложений с архитектуры "файл-сервер" [2, 4, 5] на архитектуру "клиент-сервер", которая является следующим этапом в развитии СУБД [2 - 7]. Характерная особенность архитектуры "клиент-сервер" – перенос вычислительной нагрузки на сервер БД (SQL-сервер) и максимальная разгрузка приложения клиента от вычислительной работы, а также существенное повышение безопасности данных – как от злонамеренных, так и просто ошибочных изменений. БД в этом случае помещается на сервере, как и в архитектуре "файл-сервер", однако прямого доступа к БД из приложений не происходит. Функции прямого обращения к БД осуществляет специальная управляющая программа - SQL-сервер, которая является неотъемлемой частью СУБД.
Взаимодействие сервера БД и прикладной программы-клиента происходит следующим образом: клиент формирует SQL-запрос и отсылает его серверу. Сервер, приняв запрос, выполняет его, и результат возвращает клиенту. В прикладной программе клиента в основном осуществляется интерпретация полученных от сервера данных, реализуется часть бизнес-правил и интерфейса пользователя для манипулирования данными.
Многие из уже существующих систем "клиент-сервер" создавались на базе прикладных программ, которые работали с локальными БД, используемых совместно и размещенных в сетях персональных компьютеров на файловых серверах. Перенос на SQL-серверы СУБД файл-серверной архитектуры осуществлялся с целью повышения эффективности их работы, защищенности и надежности БД.
Модель архитектуры "клиент-сервер" предполагает наличие нескольких уровней. Двухуровневая модель, возможно, наиболее общая, поскольку она следует схеме построения локальных БД (рис. 1.1). В этой модели данные постоянно находятся на сервере, а программное обеспечение доступа к данным — на компьютере пользователя. Бизнес-правила при этом могут располагаться на любом из компьютеров (или даже на обоих одновременно).
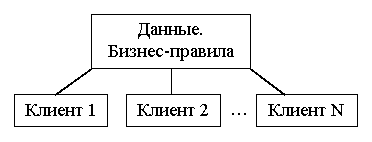
Рис. 1.1. Двухуровневая модель "клиент-сервер"
В трехуровневой модели "клиент-сервер" (рис. 1.2) в программном обеспечении клиента реализован лишь пользовательский интерфейс доступа к данным, которые находятся на сервере. Прикладная программа клиента выполняет запросы для получения доступа или изменения данных через сервер прикладных программ или сервер Remote Data Broker (Удаленный брокер-сервер данных) - RDB. Обычно бизнес-правила располагаются именно на сервере RDB. Если клиент, сервер и бизнес-правила распределены по отдельным компьютерам, разработчик может оптимизировать доступ к данным и поддерживать их целостность при обращении к ним из любых прикладных программ во всей системе.
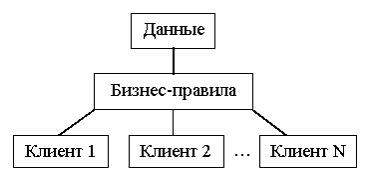
Рис. 1.2. Трехуровневая модель "клиент-сервер"
Архитектура "клиент-сервер" имеет ряд преимуществ:
- Большинство вычислительных процессов происходит на сервере, что снижает требования к вычислительным мощностям компьютера клиента.
- Минимизируется сетевой трафик за счет посылки сервером клиенту только тех данных, которые он запрашивал. Например, если необходимо сделать из файла объемом 10 000 записей выборку, результатом которой будут всего 2 записи, сервер выполнит запрос и перешлет клиенту набор данных из 2 записей.
- Упрощается наращивание вычислительных мощностей в условиях развития программного обеспечения и возрастания объемов обрабатываемых данных. Проще и дешевле увеличить вычислительную мощность сервера или заменить его на более мощный, чем наращивать мощности 100 - 500 компьютеров клиентов.
- БД лучше защищена от несанкционированного доступа, т.к. представляет собой, как правило, единый файл, где находятся таблицы, ограничения целостности и другие её компоненты. Взломать такую БД, даже при наличии умысла, достаточно тяжело. Значительно увеличивается её защищенность от ввода неправильных значений, поскольку SQL-сервер автоматически проверяет их соответствие наложенным ограничениям и автоматически выполняет бизнес-правила. Кроме того, сервер отслеживает уровни доступа для каждого пользователя, и блокирует попытки выполнения неразрешенных для него действий. Все это позволяет говорить о высоком уровне безопасности, обеспечивающем ссылочную и смысловую целостность информации.
- Сервер управляет транзакциями и предотвращает попытки одновременного изменения одних и тех же данных. Различные уровни изоляции транзакций позволяют определить поведение сервера при возникновении ситуаций одновременного изменения данных.
- Безопасность системы возрастает за счет переноса большей части бизнес-правил на сервер. Падает удельный вес взаимоисключающих бизнес-правил в ПО клиента, которое выполняет разные операции над БД. В большинстве случаев противоречивые действия будут отклонены ввиду автоматического отслеживания SQL-сервером ссылочной целостности данных.
1.4. Жизненный цикл базы данных
Жизненный цикл БД неразрывно связан с жизненным циклом информационной системы [1, 3, 4, 6, 8]. Он состоит из таких этапов (рис. 1.3) [4]:
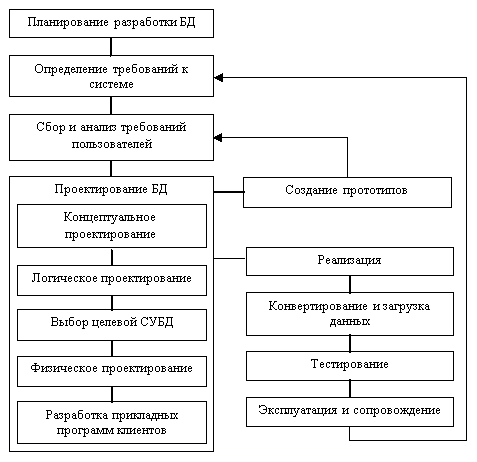
Рис. 1.3. Жизненный цикл БД
- Планирование разработки БД. Планирование самого эффективного способа реализации этапов жизненного цикла системы.
- Формулирование требований к системе. Определение диапазона действия и ограничений БД, состава её пользователей и сферы применения.
- Сбор и анализ требований пользователей. На этом этапе выполняется сбор и анализ требований пользователей из всех возможных областей применения.
- Проектирование БД. Полный цикл разработки включает концептуальное, логическое и физическое проектирование базы данных, а так же разработку прикладных программ клиента.
- Разработка прикладных программ. Определение пользовательского интерфейса, перечня и функций прикладных программ, которые работают с БД.
- Создание прототипов (необязательно). Здесь создается рабочая модель БД, которая позволяет разработчикам или пользователям представить и оценить окончательный вид и способы функционирования системы.
- Реализация. На этом этапе в программном коде реализуется концептуальная внешняя и внутренняя функциональность БД и прикладного ПО, определенные на предыдущих этапах.
- Конвертирование и загрузка данных. Процесс, который заключается в преобразовании и загрузке данных (и прикладных программ) из старой системы в новую.
- Тестирование. БД тестируется с целью обнаружения ошибок, а также его проверки на соответствие всем требованиям, выдвинутыми пользователями.
- Эксплуатация и сопровождение. На этом этапе БД считается полностью разработаной и реализованой. Впредь вся система будет находиться под постоянным наблюдением и соответствующим образом поддерживаться. В случае необходимости в функционирующее прикладные программы могут вноситься изменения, отвечающие новым требованиям. Они реализуются с помощью повторного выполнения некоторых этапов жизненного цикла.
Для малых БД с небольшим количеством пользователей жизненный цикл может оказаться не очень сложным. При проектировании больших приложения БД, с десятками и даже тысячами пользователей, сотнями запросов и прикладных программ, он может стать чрезвычайно сложным.
Следует признать, что приведенные этапы не являются строго последовательными, а включают некоторое количество повторов предыдущих шагов в виде циклов обратной связи. Например, при проектировании БД могут возникнуть проблемы, для разрешения которых потребуется вернуться к этапу сбора и анализа требований. Циклы обратной связи могут возникать почти между всеми этапами. Мы рассмотрели наиболее очевидные из них.
- Что такое информационная система организации и из каких компонентов она состоит?
- Как ручные картотеки приспособлены для хранения и обработки данных?
- Дайте определение файловой системы с точки зрения хранения и управления данными.
- К чему ведут известные Вам ограничения файловых систем как хранилищ данных?
- Что такое база данных? Дайте определение.
- Какие преимущества и недостатки СУБД Вы знаете?
- Сравните известные Вам архитектуры СУБД.
- Какие недостатки СУБД архитектуры "файл-сервер" Вам известны?
- Какие преимущества СУБД архитектуры "клиент-сервер" Вы знаете?
- Дайте характеристику моделям архитектуры "клиент-сервер".
- Какая функциональная разница между серверной и клиентской частями СУБД архитектуры "клиент-сервер"?
- Что такое бизнес-правила? Как они реализуются?
- Что Вам известно про этапы жизненного цикла БД?
Вывод
СУБД архитектуры " клиент-сервер" - неотъемлемый компонент современной информационной системы организации. Жизненный цикл БД неотделим от жизненного цикла информационной системы. Его этапы и сложность обратных связей зависит от направленности и масштаба деятельности организации.