Purpose
The objective of the chapter is to determine the position of DBMS in the information system of the organization as its essential part. Brief description of different DBMS technologies, comparison of DBMS architecture, acquaintance with data life cycle
Database (DB) is shared data connection and description dedicated for information necessity of the organization [4].
Database management system (DBMS) is a combination of language and software tools designed to create, maintain and share a database by many users. [4].
DBMS is an essential part of information system of the organization [1-3].
Information system is a resource that provides the possibility to realize data collection, modification and spread of the information inside the organization [4].
Typical computerized information system includes the following components:
- database;
- database software;
- application software;
- hardware support including saving technique;
- staff that designs and uses the system.
1.2. Manual files – file system – up-to-date DBMS
Lets give the definition of data saving and management methods that are used by information systems of the organization [4].
Manual files provide the possibility to handle the information processing when quantity of objects that are saved is small. They can be used for saving and collecting big amount of data but do not fit for occasions when it is necessary to set up cross-connections or to realize the information processing. If we need any information we have to look through files from the very beginning to the end to find necessary data. To provide the possibility of the scanning some indexing algorithm is supposed to be applied. It helps to hasten data scanning. For example, it is possible to use special separator or isolated folders for different types of objects that are logically connected.
File systems is a group of programs that perform some operations, for example - reports generation. Each program identifies its own data and controls them [2, 4, 5].
File systems was the first attempt to computerize well-known manual files. They were designed due to necessity to get more efficient data access. However, instead of organizing centralized storage for all data, the decentralized system was applied. It means that employees of each department with the help of data processing experts could work with their own data and save them in their own department.
Such brief description of file systems is enough to understand their disadvantages.
- data separation and isolation;
- data duplication;
- data dependence;
- data format incompatibility;
- rapid increase of quantity of the application programs that are necessary for collecting information.
Data separation and isolation causes significant complications when it is necessary to organize data processing in two within bigger quantity of files.
Data duplication causes uneconomical resources loss as additional data input requires additional time and funds. It can lead to data corruption. For example, we can get two conflicting answers for the same query in different departments of the organization. In many cases it is possible to avoid data duplication by applying common files use.
Data dependence causes significant loss in case of physical modification of the files structure that is presented in the applied software. For example after some period of industrial exploitation of the application program was found that number of bank account is increased from 10 to 16 signs due to some legislation amendments. To resolve the problem it is necessary to design a program that will be used only once. It has to open primary file, create temporary file with a new structure, to read data from primary file, to modify the data format and to log them to the temporary file, to remove primary file, to assign a name to the temporary file.
Data format incompatibility complicates data processing even more than data distribution and isolation. For example, it can be a result of data sharing between two local tasks. In such case it is necessary to create software that can convert data in one common format. That gives the possibility of coprocessing.
Rapid quantity increase of application programs for data collection , that is necessary for file systems users significantly depends on software experts as they have to create all queries and reports. The result was the following: in organizations, where software experts were absent in the staff list, types of queries and reports that were created corresponded to the determined format. There were no means of creation unplanned or spontaneous requests. In other companies that hired software experts quantity of files and application programs increased dramatically. Finally the moment came when it was already impossible to manage all queries for providing information to users.
Mentioned file systems limitation is a result of two factors.
- Data specification is implemented within application programs and is not saved independently and separately.
- Apart from application programs no other data access and processing tools are provided.
To improve efficiency of work new principle was applied. That is DB and DBMS.
To deepen into this concept we are going study it more carefully. DB is a united data storage that is once determined and then applied by many users from different departments. Instead of spill files all data is gathered together with minimal part of excessiveness. Database doesn’t belong to only one department, but is a public resource of corporation. It contains not only work data but also its description. That is why it is called integrated logging set with self-description. Altogether this is system catalog or data-dictionary, and the elements of description are used to be called meta-data, that means "data about data". The presence of data self-description provides independence of application programs and data (program-data independents).
Today, the use of a DBMS has the following advantages:
- control over data excessiveness;
- exclusion of data contradiction;
- data sharing;
- data integrity support;
- improved safety;
- simplification of system cropping;
- possibility to find a compromise in case of conflicting objectives;
- improvement of accessibility and their readiness for work;
- improvement of efficiency and capability;
- simplification of system maintenance due to the data independence;
- improvement of parallel data processing control;
- development of file backup and updating service,
and disadvantages:
- complexity;
- size;
- cost;
- additional expenses for hardware;
- expenses for data converting;
- more serious consequences in case of system failure.
1.3. Comparing DBMS file-server architecture with DBMS client-server architecture
1.3.1. Main components of DBMS software
Server is a hardware-software complex that processes the request.
As a matter of fact, it is waiting when a client will make a request and processes it. Server has to be able to process several requests from different clients at a time and also be able to determine priority. Usually server-side code works continuously to provide uninterrupted access to its service.
Clients are applications that provide a graphical or other user interface.
Application programs provide users with interface to manage server data. Through application program user gets the access to server features. Reception, splitting, modifying and deletion of the information and print-out of the report can be as an example of requested action. In this case client just sends a request and provides data necessary for its processing. Server is responsible for the request processing. It means that client ca not execute any logic operations by himself. It is possible that client implements the biggest part (or even whole volume) of business-rules support.
Business rules is a managing procedure that determines which client gets access and can handle data on the server.
These rules are implemented by program text of the client, server or both of them. From the side of server business rules are realized as saved procedures, triggers and other objects that are typical for server DB. It is important to understand that business rules determine the behavior of the whole system. If they are absent you just have data on one computer and application program with interface on another one, however you don’t have method to connect them.
If the biggest part of rules is implemented on the server, it is called “thick server”. If the rules are implemented on a medium level, server is also called “thick”. Where business rules are to be implemented is determined by the volume and type of necessary control operations.
1.3.2. DBMS file server architecture
DB on personal computers were developing from the basis of local application programs, when in fact only one application program can work with DB, up to systems of multiple access [2 – 7].
Necessity of multiple accesses to the same data caused DB transference to the file server. Application program that works with DB also was placed on the server. Method that implies saving of the application program that made a request to the DB on the user’s (client’s) computer, happened to be not so popular. New versions of local DBMS were issued. They provided possibility to create application programs that work with one DB on the file server simultaneously. The main problem was explicit or implicit transactions processing and the problem of providing semantic and reference integrity of the DB during simultaneous data modification implemented by several clients that unavoidably arises in case of shared access.
During exploitation of local systems, the following disadvantages of file-server data saving, that provides database access for many users, were detected:
- Whole computing load during the access to the DB is incumbent upon clients’application program that is a result of “file server” system information processing mode: in the presence of data access request the whole DB table is copied to the client’s computer, where the processing is realized.
- Resources of client’s computer and net are used not in optimal way. For example if according to a request we should get 2 records from a file that contains 10 000 records, all 10 000 records will be copied from file server on the computer of a client. As a result network traffic increases and requirements for system’s hardware capacity also increase. It is necessary to underline, that requirements for computing power of the client’s machine increases not only due to the development of software, but also because of the growth of volume of the information in process.
- It is much easier to make changes in the separate tables of the DB directly from tools, passing application clients’ programs. Such a possibility is available because in local DBMS database is a logic conception rather than physical, as we mean database to be a set of separate files that are located on the integrated disk directory. All these particularities cause low security level if we consider unauthorized access and harm, the same as mistaken changes.
- Business rules in file server systems are implemented in application problems. This gives us a possibility to apply mutually exclusive business rules. However semantic integrity of the information can be ruined.
1.3.3. Client-server architecture
Abovementioned disadvantages can be resolved by transferring from “file-server” architecture [2, 4, 5] to “client-server” architecture that is a next step in DBMS development [2…7]. Particularity of “client-server” architecture is that computing load is moved on DB server (SQL-server) and the application program of client unloaded as much as possible. There is also a significant improvement of the data protection either from ill-intentioned or erratic changes. In this case DB is located on the server as in “file-server” architecture, but there is no direct access to the DB from application programs. Service of direct connection to the DB is implemented by special control program – SQL-server that is an essential part of DBMS.
Interaction between DB and client’s application program is carried out as following: Client makes SQL-query and sends it to the server. Server that received the query carries it out and returns the result back to the client. Basically application client-program realizes interpretation of received from server data, input of the data and implementation of some business rules.
Many of already existing “client-server” programs started from application programs that applied local DB, that were shared and were placed in the personal computers network on file servers. Transfer of the file-server architecture on SQL-server DBMS was implemented to increase the efficiency of its work, safety and database reliability.
Model of “client-server” architecture supposes application of several levels. Maybe two-level model is more popular as it sticks to the scheme of local DB construction (figure 1.1.) In this model data is constantly located on the server and data access software is located on the user’s computer. At the same time business rules can be located on any computer (or even on both computers at the same time).
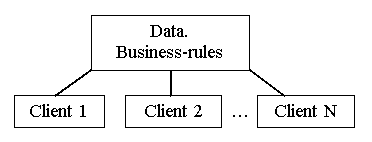
Fig. 1.1. Two-level "client-server" model
In three-level “client-server” architecture model (fig.1.2) in the software of the client only the interface of user is realized. It provides access to the data located on the server. Application program of the client runs request to get the access to the data through application programs server or Remote Data Broker – RDB. Usually business-rules are located on the RDB server. If client, server and business rules are spread among separate computers the designer can optimize access to data and support its integrity in case of request for any application programs in the whole system.
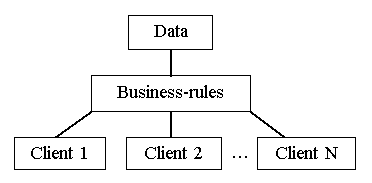
Fig. 1.2. Three-level "client-server" model
“Client-server” architecture has several advantages:
- Main part of computational processes is carried out on server that lowers requirements to the computing powers of the client’s computer.
- Network traffic is minimized by means of sending requested data by the client’s server. For example, if it is necessary to select just 2 logs from a file of total volume 10 000 logs, server runs the request and sends 2 logs data set to the client.
- Growth of computing power in the framework of software development and increase of information volume becomes simpler. It is easier and less expensive to increase computing power of the server or to change it for one with bigger capacity, than to increase power of 100-500 computers.
- Database is better protected from unauthorized access just because it is an integrated file that contains tables, limitations of integrity and other components. To crack such DB is rather difficult. Its becomes much more protected from input of illegal values because SQL-server carries out automotive check-out of their correspondence to determined limits and automatically runs business rules. Also server tracks access levels for each user and blocks attempts to run illegal processes. This permits us to speak about much higher security level and provides reference and semantic integrity of the information.
- Server realizes management of transactions and prevents attempts of simultaneous modification of the same data. Different levels of transactions isolation provide the possibility to determine the server policy in case of simultaneous modification of data.
- Safety of the system increases thanks to migration of the bigger part of business rules on the server. Specific power of mutually exclusive business rules of the client’s software that runs different processes on the database decreases. In most cases mutually exclusive actions will be rejected through automatic check-out of data reference integrity realized by SQL-server.
Data base life cycle is an essential part of information system life cycle [1, 3, 4, 6, 8]. In includes the following stages (fig. 1.3) [4]:
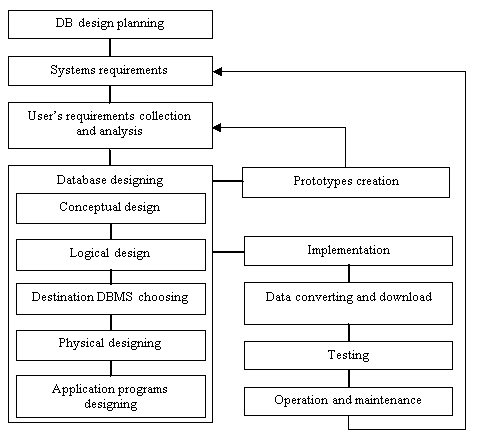
Fig.1.3. Database life-cycle
- DB design planning. Planning of the most efficient implementation of system’s life cycle stages.
- Systems requirements definition. Definition of DB range and limits, list of users and area of application.
- User’s requirements collection and analysis. On this stage users requirements collection and analysis is realized from all possible areas of application.
- DB designing. Complete cycle of designing involves conceptual, logic, and physical DB design together with client application programs designing.
- Application programs designing. Choice of user’s interface. List and functions of application programs that work with DB.
- Prototypes designing (not necessary). Here the release DB model is created. It provides the designers or users the possibility to make an idea and estimate final form and running of the system.
- Implementation. On this stage the internal and external conceptual DB and software functionality, that were defined during previous stages, are implemented in the program code.
- Data converting and download. The process of converting and downloading data (and applications) from the old system into a new one.
- Testing. DB is tested to detect possible errors, to check its correspondence to all requirements of users.
- Operation and maintenance. On this stage DB is considered to be completely designed and implemented. In the future the whole system will be under continuous control and is duly supported. If it is necessary operational application programs can be modified according to new requirements. They are realized by means of repeat implementation of some life-cycle stages that were converted before.
For DB with a small quantity of users the life-cycle can be not very difficult. However it can become extremely complicated while designing of big DB with tens and thousands of users, hundreds of requests and application programs.
It is necessary to admit that abovementioned stages are not strictly logical, but include several repetitions of the previous steps in the form of feedback. For example some problems can arise during DB designing. To resolve these problems it will be necessary to return back to the stage of collecting and analyzing requirements. Feedback cycles can appear between almost all stages. We highlighted the most obvious ones.
- What is organization information system and what components it includes?
- How are manual files adopted to data saving and processing?
- Give the definition of file system considering data saving and management.
- What is the result of file systems limitations that are familiar to you?
- What is database? Give definition.
- What advantages and disadvantages of DBMS you know?
- Compare DBMS architectures that are familiar to you.
- What disadvantages of “file-server” architecture DBMS you can list?
- What advantages of “client-server” architecture DBMS you can list?
- Give the definition of “client-server” architecture models.
- What is functional difference between server and client parts of “client-server” architecture DBMS?
- What are business rules? Where they are implemented?
- What do you know about stages of DB life-cycle?
Conclusion
“Client-server” architecture DBMS is an essential component of the up-to-date information system of the organization. DB life cycle is not separated from the life cycle of information system. Its stages and complicity of feedback depends on the kind of activity and size of the organization.